Programming the Fundamental Theorem of Calculus
This week's post is a bit of an odd experiment. The advanced study of Probability Theory requires an increasingly sophisticated understanding of the Integral. However, one of the most popular books purchased from the recommended reading page is Calculus Made Easy. The focus of this blog definitely not being Calculus, I'm not quite sure how far back to take the subject. So in this post we're going to start with a rather odd way of understanding the Fundamental Theorem of Calculus, which is as good as any a place to start understanding the fascinating nuances of Integration Theory. If you need a quick introduction to Calculus itself I recommend watching my short video on Counting to Multivariable Calculus in Five Minutes.
The Fundamental Theorem of Calculus is truly one of the most beautiful, and elegant ideas we find in mathematics. It relates the Integral to the Derivative in a marvelous way. There are two parts to the theorem, we'll focus on the second part which is the basis of how we compute Integrals and is essential to Probability Theory. The second part of the Fundamental Theorem of Calculus States$$\int_{a}^{b} f(x)dx = F(b) - F(a)$$ Where \(f(x)\) is the derivative of \(F(x)\), or we can refer to \(F(x)\) as the Antiderivative of \(f(x)\). In English this states: "The area under the curve from \(a\) to \(b\) of a function \(f\) is just the difference between the values of that function's antiderivative, \(F\), at \(b\) and \(a\)."
To give a simple example we can look at \(x^2\). Since \(x^2\) is the derivative of \(\frac{1}{3}x^3\) for any given \(a\) and \(b\) we can calculate the area under the curve of \(x^2\) as simply:$$\int_{a}^{b} x^2dx = \frac{1}{3}b^3\ - \frac{1}{3}a^3$$ And, more specifically we could cacluate the Integral of \(x^2\) between 2 and 100:$$\int_{2}^{100} x^2dx = \frac{1}{3}100^3\ - \frac{1}{3}a^3 = \frac{1,000,000}{3} - \frac{8}{3}\ \approx 333,331$$
When I initially encountered the Fundamental Theorem of Calculus, my first thought was "it's that great that it works out that way!" Unfortunately it was not obvious why this was the case. Typically if I don't understand something I visualize it to see what it looks like. Here is a plot comparing \(x^2\) and \(\frac{1}{3} x^3\):

At least for the case of \(x^2\), the relationship between the derivative and the antiderivative never struck me as obvious. It certainly looks like it works, but the intuition as to "why" wasn't clear. Part of the problem is that we're only looking at a part of functions that can take on an infinite domain of values. We really can't visualize the entire thing.
Perhaps we can solve this problem by looking at a function that is defined on a bounded domain.
Another way to Integrate
Let's look at our good friend the Beta distribution, we'll use Beta(2,16). Unlike \(x^2\) the Beta distribution is only defined on the domain \([0,1]\). Here is the Probability Density Function (PDF) for Beta(2,16).
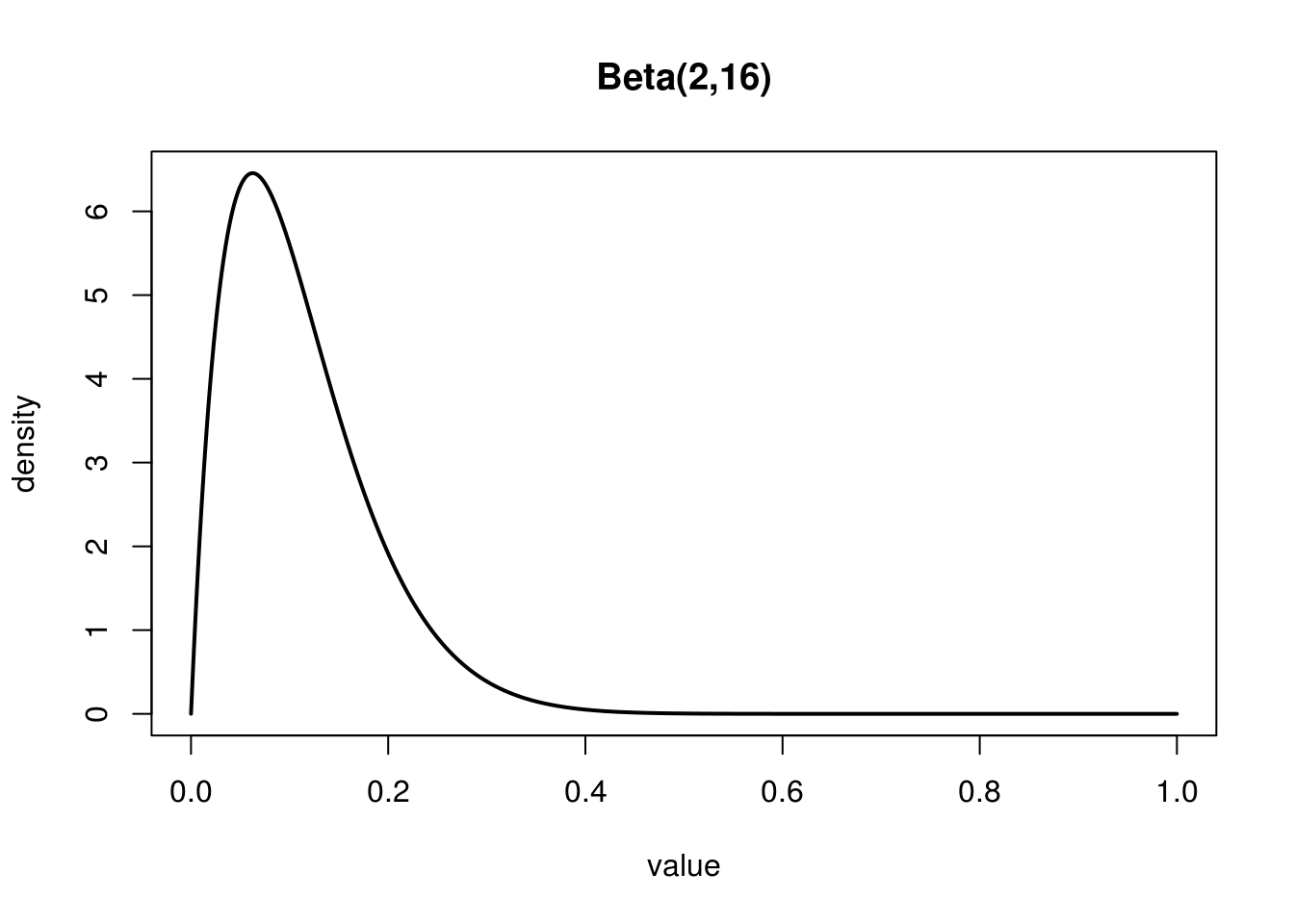
Starting by calculating a function's antiderivative is not actually my favorite way to compute the Integral in practice. In case the reason for this is not clear here is definition of the PDF for the Beta distribution:$$Beta(\alpha,\beta) = \frac{x^{\alpha - 1}(1-x)^{\beta -1}}{B(\alpha ,\beta)}$$
Feel free to calculate its antiderivative at your leisure!
There is a much simpler way to approximate the integral of a function to a reasonable precision (and since probability is about uncertainty there's always a sane number of significant figures you care about). What we're going to do is simply make a discrete approximation of the integral. Say we want to determine$$\int_{0.2}^{0.4} Beta(2,16)$$
In R we can simply calculate the value of \(Beta(2,16)\) in discrete chunks like this:
dx <- 0.0001 xs <- seq(0.2,0.4,by=dx) approx.int <- sum(dbeta(xs,2,16))*dx
This just approximates the curve as a bunch of \(dx\) wide towers of heights \(f(x)\). It should be noted that there are much better ways to approximate integrals (which I plan to cover in a future posts) and that R itself has a really nice integrate function which will give you better precision than the code above. We're now pretty far from the elegant world of the Fundamental Theorem of Calculus (hereafter abbreviated as "FToC"). With this alternate view of the Integral, we'll go ahead and build something very useful for everyday applications of probability.
Building the Cumulative Distribution Function
Let's forget about Calculus for just a second and build one the most useful tools for practical applications of Probability: the Cumulative Distribution Function (CDF). Even if you've never heard of the CDF, it's something that you would likely invent anyway. We covered the used of the CDF at length in a previous post, but in simple terms it takes the total probability of events less than a given \(x\). For a discrete probability distribution this is easy. For an example take \(Binom(5,0.2)\):

To compute the CDF we can just add up the total probability covered as we go!

The CDF answers questions such as "What is the probability of getting less than 3 heads?" or even "What is the probability of getting between 3 and 5 heads". It is an extremely useful tool that, even without a formal definition or name, would likely arise naturally from the kinds of questions we're interested in answering.
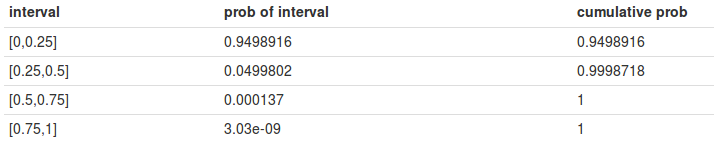
Solving this problem for discrete functions is trivial, but what about continuous functions like \(Beta(2,16)\)? We already worked out a way to approximate the integral; let's start by simply breaking up the domain of the function into discrete chunks. We'll start with splitting into fourths. Here is the code we're going to use (this code is deliberately less abstract/clean than it could be to make the reasoning clear):
dx <- 0.00001 #define our intervals interval.1 <- seq(0,0.25,by=dx) interval.2 <- seq(0.25,0.5,by=dx) interval.3 <- seq(0.5,0.75,by=dx) interval.4 <- seq(0.75,1,by=dx) #define the probability for the interval use the integral definition from previous section p.int.1 <- sum(dbeta(interval.1,2,16))*dx p.int.2 <- sum(dbeta(interval.2,2,16))*dx p.int.3 <- sum(dbeta(interval.3,2,16))*dx p.int.4 <- sum(dbeta(interval.4,2,16))*dx #define the cumulative probability for the interval p.cum.1 <- p.int.1 p.cum.2 <- p.int.1 + p.int.2 p.cum.3 <- p.int.1 + p.int.2 + p.int.3 p.cum.4 <- p.int.1 + p.int.2 + p.int.3 + p.int.4
and here is our cumulative probability table:
This is a good start but clearly we need need to break this into smaller intervals and the code from the last example will get too messy for that. Here's an abstracted version of that code so we can just set our interval size and get a list back with our individual and cumulative probabilities.
cum.dist <- function(interval.size){ dx <- 0.00001 #figure out the starts of our intervals int.starts <- seq(0,1-interval.size,by=interval.size) #determin the probability for each interval probs <- sapply(int.starts,function(n){ #then just integrate the interval as we've been doing xs <- seq(n,n+interval.size,by=dx) sum(dbeta(xs,2,16))*dx }) #the cumulative sum function (cumsum) will handle #generating the cumulative probabilities quite nicely cum.probs <- cumsum(probs) #finally return it all as a list return(list(prob=probs,cum.probs=cum.probs)) }
And rather than print out a bunch of long tables we can just plot out the cumulative probabilities for decreasing intervals.

By the time the interval size is 0.01 we get a pretty smooth line. But wait a second! If you look carefully at the code you'll realize that when interval.size = dx then the sequence generated when calculating probs will just cover the distance dx! Discretizing our already discrete proximation is redundant, and we can now dramatically simplify the code. We can finally rewrite our approximation of the Cumulative Density Function as:
our.cdf <- function(dx){ xs <- seq(0,1,by=dx) cumsum(dbeta(xs,2,16)*dx) }
Now we get to something really interesting! R has another useful function `diff` which takes the difference of each consecutive point in a sequence so that
diff(c(1,2,3,4,5)) == c(1, 1, 1, 1)
and also that
diff(cumsum(c(0,1,2,3,4,5))) == c(1, 2, 3, 4, 5)
Which means diff essentially undoes cumsum.
Now we'll slowly step out of code and back into math and see where we end up. Let's just convert some of our code into symbols:
$$pdf := \text{dbeta(xs,2,16)}$$This assignment just takes our actual computation of the PDF and represents it as a single symbol \(pdf\).
$$cdf := \text{(cumsum(dbeta(xs,2,16)*dx)}$$Similiar to the previous case we're simply taking our computation, which mathematics does not care about, and replacing it with a symbol which corresponds to the meaning of that computation.
Now we can look at the 'diff' as just 'little differences' so we can use the common \(dy\) notation here and it will mean essentially what it does in standard calculus notation.
$$dy := \text{diff(cdf)}$$
Now we can show something really neat. Since diff just undoes cumsum we know that$$\text{diff(cdf)} = \text{pdf}\cdot dx$$
So clearly then:
$$dy = \text{pdf}\cdot dx$$
And via basic algebra:
$$\frac{dy}{dx} = \text{pdf}$$
Which is to say that the PDF is the derivative of the CDF, and therefore the CDF is the antiderivative of the PDF! Through a completely discrete and algorithmic means we have clearly show that the CDF is the antiderivative of the PDF. As we have shown in the past, and anyone familiar with the practical use of the CDF the difference between the CDF at two point show the total probability between those two values:$$\int_{a}^{b}\text{pdf}\cdot dx = \text{cdf}(b) - \text{cdf(a)}.$$This is simply computing the integral of the PDF as explained by FToC! If you followed the R code you have followed the essential reasoning why FToC actually works. There you have it: a rather strange way to show the reasoning behind the Fundamental Theorem of Calculus.
Conclusion
The CDF is simply the Antiderivative of the PDF. This makes sense since we use the CDF to quickly look up the probability for ranges of values which is exactly what Integration does. If you can understand how to write the code to compute the Cumulative Distribution Function from scratch, then you also understand how the FToC relates the derivative of a function to its integral!
While beautiful, it turns out that the FToC is actually not strong enough to deal with all of the cases of integration we come across in Probability. In a few upcoming posts we'll explore how we can develop more robust (though admittedly less elegant) ways to define the Integral to help us solve these problems.
If you enjoyed this post please subscribe to keep up to date and follow @willkurt!